The conversation always seems to start with slow Wi-Fi, doesn’t it?
Maybe its employees telling you that they’re getting kicked-off of the Wi-Fi at your office. Or maybe you’re just tired of having the receptionist reboot your access points every other day (even if that seems to fix things for a bit). Bottom line… if you can watch Netflix in bed from your iPad, then you at least better be able to check email at the office! What if the quality of your Wi-Fi connection at work was top-notch? What if you knew you could support hundreds of connections – phones, laptops, tablets… and you knew that they’d be able to work on-line without headaches, without downtime… and most of all, without complaints every other day? Would you be interested?
Of course it’s possible, in fact the expectation today should be consistent and reliable Wi-Fi.
In 2015, we’re in what’s called the 5th Generation of Wi-Fi/wireless technology, having finally arrived in the 802.11ac era. This represents the fifth major iteration of the Wi-Fi as a technology standard. It’s hard to believe when you look back, but Wi-Fi is now more than 18 years old. What started off in the late 1990s with 2Mbps data rates, and a platform designed for the occasional use in conference rooms, has evolved into a standard that can support gigabit speeds, dense user populations, and video streaming without breaking a sweat.
In other words, if you have slow Wi-Fi service today, it’s a problem that can be solved.
Why is your current Wi-Fi slow?
A common narrative goes something like this… “We’ve been using these wireless access points for a while, and up until recently we almost never had a problem. Now? Everything just seems really slow. We reboot the APs every so often and that seems to help… for a while… but the problem isn’t going away.
Often times, a quick walkthrough reveals a mix of consumer grade APs, placed at random throughout the environment. While that’s not necessarily a root cause, it is a warning sign, and at the very least something to investigate. What can make this especially challenging for the average business owner is that the design of their wireless network (WLAN) probably served them reasonably well up until fairly recently. The explosion of portable devices and increasing end-user expectations are the major market forces at work, combining to strain older WLANs.
The flavors of 802.11
The Institute of Electrical and Electronics Engineers (IEEE) describes the 802.11 family of protocols, which provide the basis for wireless network products using the Wi-Fi brand. They whole history of the protocol family is beyond the scope of article but here’s a short summary:
- 1997 – 802.11 supports up to 2 Mbps
- 1999 – 802.11b supports up to 11 Mbps
- 2002 – 802.11a/g supports up to 54 Mbps
- 2007 – 802.11n supports up to 600 Mbps
- 2012 – 802.11ac supports up to 3.6 Gbps
What’s a bit misleading is that just because the 802.11ac standard was ratified in 2012, doesn’t mean that mature Enterprise 802.11ac access points were available at the time. For example, while Quantenna and Broadcom were shipping Wi-Fi chipsets in 2012, and there were a couple of consumer grade 802.11ac access point that year, it wasn’t until over a year later that Cisco shipped 802.11ac in their Aironet product line-up. It was even later than that for Ruckus. What you may or may not realize, is that vendors like Cisco, Ruckus, Aruba, HP, Apple, etc. don’t actually make the Wi-Fi chip-sets that go into their products. Instead, similar to the manner in which Dell buys CPUs from Intel – what the vendors do is contract with a chipset vendor like Atheros, Broadcom, or Marvell. The chipset vendors take the 802.11 standard specifications, and design chipsets that actually implement the 802.11ac standard. The chipsets typically include the chips that implement that standard, and may also include software drivers, and maybe an operating system to run the chipsets. The major integrators of the world then buy the chipset and related components in volume from the upstream vendors, and implement those chipsets in their hardware in the form of a product like Cisco’s Aironet, or Ruckus’s R700 access points.
So if everyone is using the same basic building blocks, what differentiates the products?
The same thing that differentiates say, a Samsung Galaxy Android phone, from an Apple iPhone… it’s about how well the components work together, and the experience they provide end-users. Starting early in a product lifecycle – say the first generation of 802.11ac, there’s usually relatively little “value-add” that the vendors build into the product. The first generation is often mostly about integrating the various hardware components effectively. As they iterate through designs, vendors build their own intellectual property on-top of the chipsets to diversity their offering relative to the competition. In the case of Ruckus, a major component of their intellectual property, or their value-add comes in the form of the antenna system (more below), which differentiates their offering fundamentally from most of the omnidirectional antenna competition. But all of this takes time. Even today, with 802.11ac several years old (at least on paper), 802.11ac Enterprise-class hardware has is still somewhat recent, and is still improving as “wave 2” 802.11ac devices start popping up on the horizon.
So what do I get out of 802.11ac?
It’s faster, and can support more devices than the last generation of products.
How much faster? That depends on quite a few variables. Today, under certain conditions 802.11ac is up to 3x as fast today as 802.11n devices are, and it has the potential to be quite a bit faster down the line with the 802.11ac specification being written to support up to 8 antennas, multi-user MIMO, and up to 6.8 Gbps.
But we’re getting a bit ahead of ourselves.
If all you’re interested in is if it’s worth buying 802.11ac Enterprise class devices today, the answer is yes – buy 802.11ac access points… even if you don’t have enough 802.11ac client devices yet to dictate 802.11ac (and you probably don’t). Why? Because 802.11ac is backwards compatible with 802.11n, and APs supporting it are generally compatible with all major 802.11 variations in both the 2.4 GHz, and 5 GHz segments of the spectrum. Plus, because 802.11ac represents an evolution of the old 802.11n specification, by buying 802.11ac Enterprise class access points (APs) today, what you’re really doing is buying the best of the 802.11n designs, and getting 802.11ac as well.
For the majority of customers, it only makes sense to buy 802.11ac access points.
APs and Controllers?
Wireless Access Points (APs) are the devices on your network which broadcast your Wi-Fi signals, implement encryption/security and physically bridge your wired Ethernet network with your WLAN. If you’re coming at the wireless market and have experience with consumer APs, or Wi-Fi at home, the APs are what you’re probably already familiar with.
In addition to the APs themselves, most Enterprise-Class wireless solutions all but require a wireless controller. For example, Cisco and Ruckus both have controllers in the form of the Cisco Wireless LAN Controller for the Aironet products, and the Ruckus ZoneDirector controller. In broad terms, the wireless controllers extend the capabilities of the APs, and use data generated by the APs such that they’re able to work together to optimize signal, connection, and performance for the participating wireless clients.
But what do the controllers actually do?
In real-world terms, controllers do quite a few things. First, controller-based APs look for and associate with a parent controller automatically, which enables the APs to self-configure and associate with the controller making them immediately available for remote management. Once that happens, the controller can automatically optimize the environment and adjust settings on-the-fly in response to real-world measurements and feedback from the APs. This means adjusting power levels and RF channel assignments dynamically in order to minimize the impact of interference. If you recall setting up consumer-grade APs and having to manually set the channels to keep them from interfering with each other, then you’ll be pleased to learn that optimizations like that will happen automatically and without administrative burden on an on-going basis, providing the best possible signal quality to your end-user’s devices. Beyond optimizations, the controller also provides value-added troubleshooting capabilities that can not only consolidate logging information, but also enable an administrator to determine individual client-device performance. Translated, that means you’ll potentially be able to drill-down on complaints of “My Wi-Fi is slow!” in real-time and do root-cause analysis (instead of just rebooting the AP and hoping). Beyond the above, controllers also work to enable more advanced security integration capabilities, generally enabling RADIUS, captive portal, ActiveDirectory integration, dynamic VLAN assignment, and a host of other capabilities.
Beamforming and MIMO
If you’re unfamiliar with how radio frequency (RF) energy propagates from an omni-direction antenna (e.g. a regular wifi antenna), the propagation looks like a donut-shaped Wi-Fi bubble of coverage emanating out from your APs in 3-Dimensional space.
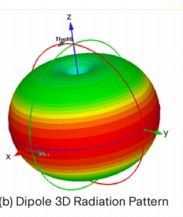
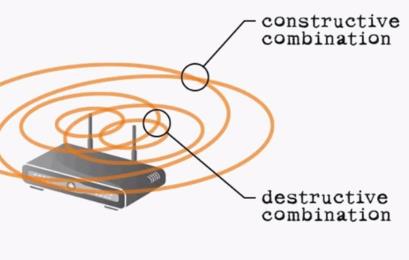
When you think about on-chip beamforming as a technology, you might think in terms of it directing RF energy in a beam-like manner toward the client devices that the AP is communicating with. Unfortunately, the reality falls somewhere short of that. In the prior standard, 802.11n specified several beamforming methods, but because there were so many options and because implementing them drove cost and complexity, the result was that most vendors didn’t implement anything on the client side. And when it comes to the on-chip variety (e.g. nearly every implementation) the benefit that beamforming created in terms of increased signal strength was often times negligible, and occasionally destructive. The problem really comes down to a lack of data. Without getting into the weeds, in a version of the 802.11n on-chip beamforming variety, a pair (or more) of omni-directional antennas emit identical signals, but because of timing or transmission paths, those signals arrive a slightly different points in time on the receiving end, with the goal being constructive interference at the point of the receiver. Something like this…
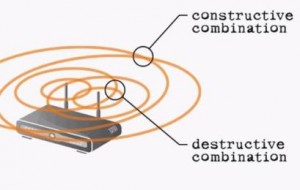
The challenge is that dead-spots and areas of destructive interference combine to minimize the benefit of on-chip beamforming advantage, resulting in coverage patterns with gaps in their effective coverage areas. There’s a lot more to this topic, but that’s the short version.
802.11ac Beamforming
With 802.11n beamforming iterations generally coming-up short, only one beamforming model was specified in 802.11ac, which works on both sides of the conversation (both the AP, and the client devices). The specification is an evolution of 802.11n, with support for more Multiple input, multiple output (MIMO) spatial streams (up to 8). In practical terms, that means up to 8 antennas on both the AP and client side of the conversation.
Big-picture? This translates into better & faster Wi-Fi.
To elaborate on MIMO briefly, MIMO relies on interference to create signal diversity, which enhances signal quality. It may sound counter intuitive at first though, so here’s a bit more of how it works. Instead of using a single carrier transmitting a data set for a short period of time, where temporary interference can damage a signal’s payload, 802.11ac MIMO specifies OFDM. Essentially, this means multiple data payloads (“symbols”) are transmitted in parallel on the same frequency, on multiple radios for longer periods of time, making it easier to recover the signal if there’s temporary interference. Essentially, all of the transmitters transmit on the same frequency, but with different data being sent out of each antenna (up to 8 antennas, in the specification). So the obvious question becomes how can multiple antennas operate at the same time on the same frequency with different data sets, and not create interference? The answer? A powerful digital signal processor (DSP) and matrix math, enables either side to recover the actual signals on each antenna. The receiving antennas are able to differentiate the data, and improve spectrum efficiency to, in real terms, multiply bandwidth by the number of radios (up to 8). In one application, 3 transmit antennas send 3 different sets of data on the same frequency at the same time, and the three receive antennas are still able to unscramble the data, because the signal diversity causes the signals to arrive at different points in time. Effectively, the signals bounce off of stuff as they propagate outward, ensuring that the signals all arrive at slightly different points in time, and when combined with a strong DSP, the AP is able to unscramble and recombine the data streams.
(What I’ve presented on MIMO is a simplified version of what’s really going on. I didn’t touch on the client-end, channel measurements that happen on both the transmit and receive sides, or multi-user MIMO. So if you’re interested in a more comprehensive answer, including a an explanation of the matrix math involved in unscrambling the data streams, check out 802.11ac: A survival guide, by Matthew S. Gast, and you will not be disappointed).
Put differently… MIMO is all about maximizing the efficient use of the RF spectrum. Which translates into more, better, faster Wi-Fi for everyone. Well, for the most part anyway. For mobile devices, particularly phones and tablets, it’s going to be quite a while before we see 8 antennas implemented. The reason for this is that each additional radio doubles the power demands, shrinking the battery life of those mobile devices. So while energy consumption may not matter at the APs, on mobile devices like phones and tablets, every milliwatt counts.
Wouldn’t directional antennas be better than omni-direction antennas?
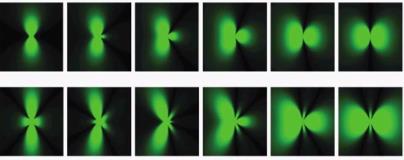
As I mentioned earlier, most APs use omni-directional antennas that radiate RF energy out indiscriminately in a 3D Wi-Fi coverage bubble. And even when you add most vendor’s beamforming flavors, you’re not doing anything to increase the size of the coverage zone. Instead, what you’re really doing is using some clever tricks to take the signal donut and alter the quality (both for good, and ill) within the existing coverage range. In practice, on-chip beamforming with omnidirectional antennas create coverage areas with improved , as well as reduced coverage, as approximated below.

And we haven’t even discussed polarization yet.
An antenna provides gain, direction, and polarity to a radio signal. Polarity is the orientation of the transmission from the antenna. Antennas produce either vertically polarized (VPOL), or horizontally polarized (HPOL) signals – the polarization axis describes the orientation of the radio waves as they radiate out from the antenna. In other words, RF energy moves in waves, and those waves move up-and-down, or back-and-fourth in space – the polarization of the wave.
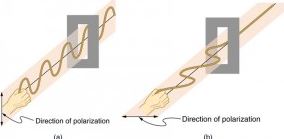
Why does polarization matter?
In a worst case scenario a perfectly horizontal receiving antenna may not hear anything transmitted by a perfectly vertical antenna. While objects can impede, or reflect a signal and distort the polarization, signal loss due to polarization differences is real, and can potentially prevent communications from occurring. At the very least, signal strength is reduced.
In terms of a real-world example, recent MacBook designs have housed their antennas in the hinge section of the laptop, and the antenna has a horizontal orientation. What this means, is that a transmission coming from a vertically polarized AP will be harder for the MacBook to hear, and likewise the AP will have a harder time distinguishing the MacBook’s transmission. For laptops, the polarization is generally a static condition based on the orientation of your laptop. Phones and tablets though? You tilt their orientation based on whatever you’re doing. Need a wide-screen to watch Netflix, you hold your phone horizontally. Reading an article on a web-site… you’ll orient it vertically. The changes in the devices physical orientation change the orientation of the RF signal. Which results in complaints along these lines; “When I hold my phone a certain way and I’m standing in this location, the Wi-Fi slows down or stops working” (that and other similarly unusual symptoms).
Here’s why… nearly all Wi-Fi access points use omni-directional dipole antennas that are vertically polarized. These are considered the norm in the industry. The reason is that they were common in the wider field of RF prior to the mass adoption of Wi-Fi. In the case of a Cisco Aironet 2700 series antenna, the omnidirectional antennas housed within the chassis are vertically polarized antennas when mounted in the traditional orientation (e.g. flat).
 To contrast Ruckus’s antenna design with omnidirectional antennas, Ruckus’s design takes a large number of small antenna elements and hooks those up to a digital switch. The AP learns about the environment, and then uses antenna element array combinations to produce a desirable coverage pattern. Some of these antenna elements are vertically polarized, and others are horizontally polarized. By leveraging the CPU in the AP, Ruckus then optimizes antenna patterns for performance, in terms of rate control, power selection, and antenna choices. Then, the choices are remembered for each client device, enabling the Ruckus product to make increasingly better decisions as the devices communicate. So even under 802.11n, where the client devices aren’t providing any beamforming feedback to the APs, the Ruckus product is still able optimize antenna patterns to maximize signal strength potential based on historical data for the individual client. This occurs in a manner that the Cisco Aironet products are fundamentally unable to do. Moreover, since the Ruckus solution uses antenna element arrays, there’s a mix of horizontally polarized, vertically polarized, as well as directional antenna elements which can create pattern optimizations that Ruckus is able to employ in order to optimize signal for both horizontally and vertically polarized client devices. Put differently, Ruckus’s antenna designs go a long way to optimizing signals for various device types in the current, bring-your-down-device (BYOD) real-world. What’s more, even though 802.11ac specifies a beamforming implementation that incorporates client device feedback into channel optimizations, Ruckus is able to optimize for signal-strength in a manner that’s fundamentally more diverse than any omni-directional antenna is able to do. While Cisco does take issue with that statement, in the form of a whitepaper outlining why DSP processing is better than using thousands of unique antenna patterns for optimizing the RF signal for real-world situations, Ruckus’s antenna arrays are physically able to compensate for RF polarization, and even increase the “Wi-Fi” bubble by employing directional antenna elements which extend RF energy physically in the direction of active clients.
To contrast Ruckus’s antenna design with omnidirectional antennas, Ruckus’s design takes a large number of small antenna elements and hooks those up to a digital switch. The AP learns about the environment, and then uses antenna element array combinations to produce a desirable coverage pattern. Some of these antenna elements are vertically polarized, and others are horizontally polarized. By leveraging the CPU in the AP, Ruckus then optimizes antenna patterns for performance, in terms of rate control, power selection, and antenna choices. Then, the choices are remembered for each client device, enabling the Ruckus product to make increasingly better decisions as the devices communicate. So even under 802.11n, where the client devices aren’t providing any beamforming feedback to the APs, the Ruckus product is still able optimize antenna patterns to maximize signal strength potential based on historical data for the individual client. This occurs in a manner that the Cisco Aironet products are fundamentally unable to do. Moreover, since the Ruckus solution uses antenna element arrays, there’s a mix of horizontally polarized, vertically polarized, as well as directional antenna elements which can create pattern optimizations that Ruckus is able to employ in order to optimize signal for both horizontally and vertically polarized client devices. Put differently, Ruckus’s antenna designs go a long way to optimizing signals for various device types in the current, bring-your-down-device (BYOD) real-world. What’s more, even though 802.11ac specifies a beamforming implementation that incorporates client device feedback into channel optimizations, Ruckus is able to optimize for signal-strength in a manner that’s fundamentally more diverse than any omni-directional antenna is able to do. While Cisco does take issue with that statement, in the form of a whitepaper outlining why DSP processing is better than using thousands of unique antenna patterns for optimizing the RF signal for real-world situations, Ruckus’s antenna arrays are physically able to compensate for RF polarization, and even increase the “Wi-Fi” bubble by employing directional antenna elements which extend RF energy physically in the direction of active clients.
In other words, Ruckus largely eliminates the polarization topic and self-optimizes polarization in favor of improved client communications. Put differently, Ruckus’s Beamflex technology is beamforming on steroids.

Unlike on-chip beamforming, the transmit beamforming via Ruckus’s antenna element array provides a fundamentally unique capability relative to the competition, with antennas capable of producing unique coverage patterns over a more focused coverage area, with less potential for destructive interference relative to omni-directional antennas.
Where do I go from here?
The Enterprise Wi-Fi industry (e.g. Enterprise WLAN market) continues to produce more capable Access Points, with more features. As more 802.11ac Enterprise-Class product sets are released, and improved upon, they’re increasingly making more efficient use of the available RF spectrum. This translates into faster Wi-Fi, in denser user environments, with increasing features and capabilities. This trend is expected to continue for the foreseeable future, as the 802.11ac specification was designed to grow around the anticipated near-term needs for more bandwidth, largly by employing more radios and antennas, as well as through the role out of MU-MIMO in wave 2.
From a marketshare standpoint, Cisco is the clearly the dominate player. As of the last published IDC marketshare report, while Enterprise Wireless LAN market grew 7.6% year-over-year…
- Cisco had 46.8% of the market, down though from 53% in the prior year
- Ruckus saw 20.8% growth in the prior year, growing to 5.7% of the market
- Aruba’s sales grew at 7.9%, increasing to 9.8% of the market.
In addition to marketshare, the biggest recent news of course, is that HP is buying Aruba, though it’s far too early to know how that will play out and what effect it will have on the market.
But which vendor is the best?
The major Enterprise WLAN vendors all offer generally competitive products, derived from just a few different chipsets. With market forces being what they are, the result is that all of these products are generally competitive. From a technical standpoint, the most recent vendor independent, access point analysis and report, comes courtesy of Wireless LAN Professionals in 2013. Notably, the event was not vendor-sponsored, and as such represents the most unbiased and comprehensive assessment that I’ve seen. It is however, limited to the last generation of 802.11n products. What you’ll find if you dig through the reports, is that every single access point reached a choking point with respect to maximizing the use of the RF spectrum. In the case of the report, the best overall combination ranking was the Ruckus 7982 product, followed by the Cisco 3602i. If you look a bit further back, Tom’s Hardware did an excellent article on beamforming – “Beamforming: The Best WiFi You’ve Never Seen”. While some of it is obviously a bit dated having been published prior to 802.11ac being standardized, it’s still a great primer on the differences between on-chip and antenna beamforming.
The real question is best for whom, or for what situation
Failing an updated version of the Wireless LAN Professional report incorporating the newer 802.11ac products, there’s not a comprehensive vendor-neutral assessment that I can point to in order to tell you which device technically has the best overall coverage in this generation of product. Even if I did, and we could, it wouldn’t effectively answer which is best for your environment. Beyond RF-capabilities, there are several factors which differentiate Enterprise 802.11ac WLAN products. These include everything from design, to ease-of-use, to management capabilities, scalability, price and more. For example, Ubiquiti offers a low-cost controller-less product, that’s generally easy to deploy and manage and is probably reasonable for most IT resources to deploy. However, you generally need more access points than you would with a Ruckus deployment, and that means potentially more troubleshooting work. And unfortunately, Ubiquiti doesn’t really offer technical support that would be comparable to any of the Enterprise-Class AP vendors. Meanwhile, the Cisco Aironet product is an Enterprise-Class access point designed by the marketshare leader, and employs Cisco’s IOS, which makes it generally more suited toward larger environments or for environments where the IT resources involved have Cisco-specific experience. Cisco has good support, but reaching the right support resources in a timely manner, and getting effective support doesn’t always happen. Ruckus on the other hand, employs a unique phased-antenna element array design that provides a fundamentally unique advantage relative to the competition, which was apparent during the last generation of products in the vendor-independent assessment. Further, Ruckus’s products are generally easy to manage and work with, and can be deployed by IT resources with moderate Wi-Fi experience, and their technical support is excellent.
In other words, it’s not necessarily a question of which access point is best, it’s a question of which access point is best for your environment and situation.
My recommendation
Having recently implemented solutions from Cisco, Ruckus, and Ubiquiti my recommendation would be based on your specific situation. But generally speaking, I do have a preference for the Ruckus product set. From a technology standpoint, Ruckus has developed a unique edge in terms of their antenna solution, which provides a fundamentally different capability relative to any of the Enterprise-class WLAN competitors. What’s more, during the last generation of products, their ranking in the independent vendor assessment implies that the adaptive antenna design is giving them an edge relative to their competition. From a support standpoint, Ruckus’s support team has been subjectively better than Cisco’s in my experience. From an ongoing management standpoint, the Ruckus ZoneDirector interface provides and good dashboard where you can easily drill down on performance and troubleshooting, without necessarily requiring the support of an IT organization or individual. While Ruckus isn’t the right solution for every situation, it is a very attractive solution that is priced competitivly with the Cisco Aironet offering.
Bottom line?
Having slow or poor Wi-Fi coverage is a solvable problem today, and 802.11ac represents the latest revision of the technology standard. At this point in the cycle, we’re starting to see mature second generation product sets coming from the major Enterprise WLAN competitors, and they all offer generally competitive and capable products. If you’re tired of struggling with unreliable Wi-Fi in your office, it’s a very solvable problem today and we’ll be able to help you find the best solution for your needs and your environment.