Back in the 90’s, before content management systems, Intranet sites, and WYSIWYG editors, web-sites were built by hand with HTML code and ASCII text editors. Folks armed with a bit of knowledge and some patience, laboriously constructed web sites. Even if you happened to use tools like the HotDog HTML editor, bringing web-sites to market was a time consuming and expensive endeavor. Fortunately, that’s no longer the case. We all know the story… web technologies, driven in no small part by the explosive growth of tablets, and smartphones, have advanced and we have a modern ecosystem that was barley hinted at in the 90s. Underpinning much of the modern web, are content management systems (CMS) like WordPress, which enable and accelerate bringing web-sites and projects to market.
My goal with this series to essentially provide small & medium sized business with a WordPress Toolkit, arming you with everything you need to know to either bring a site to market yourself, or give you enough knowledge to make good decisions when it comes to hiring a company to partner with.
What is a Content Management System
 There are probably some use cases where hand-coding web sites still makes sense. For the rest of us, content management systems (CMS) exist to save us time, and money. A CMS is a piece of software that manages web-site content. Sounds simple, right? By that definition there are hundreds of CMS platforms today, incorporating solutions as disparate as blogger.com and WordPress. You could always choose a CMS platform and hosting option in one, putting your site on somewhere like blogger.com, or the like… but why would you opt for a free site (e.g. yousite.blogger.com), where your content is really only serving to increase the value, brand, and awareness of someone else’s property? While you might choose to augment your business’s content via micro blogging and social media sites like Tumblr, Twitter, Facebook, Instagram, etc., your presence on those properties should serve to increase the brand and awareness of your business, and bring people to your web site. Think in terms of your web-site as being the hub of your presence, and spokes extending out to other properties that serve to increase your exposure.
There are probably some use cases where hand-coding web sites still makes sense. For the rest of us, content management systems (CMS) exist to save us time, and money. A CMS is a piece of software that manages web-site content. Sounds simple, right? By that definition there are hundreds of CMS platforms today, incorporating solutions as disparate as blogger.com and WordPress. You could always choose a CMS platform and hosting option in one, putting your site on somewhere like blogger.com, or the like… but why would you opt for a free site (e.g. yousite.blogger.com), where your content is really only serving to increase the value, brand, and awareness of someone else’s property? While you might choose to augment your business’s content via micro blogging and social media sites like Tumblr, Twitter, Facebook, Instagram, etc., your presence on those properties should serve to increase the brand and awareness of your business, and bring people to your web site. Think in terms of your web-site as being the hub of your presence, and spokes extending out to other properties that serve to increase your exposure.
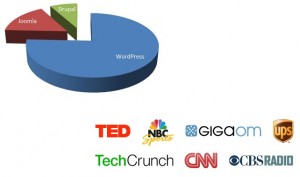
To filter down the number of CMS platforms a bit, when I talk about a CMS platform, what I’m really referring to is the mainstream open source options that are common on many hosting platforms. The top three by marketshare are Joomla, Drupal, and WordPress. Of those, WordPress accounts for roughly 75% of the CMS market, powering the infrastructure of more than 100 million web sites, including big sites that you’ve probably heard of like TechCrunch, CNN, TED, and others.
But what about… Joomla, and Drupal?
Both Joomla and Drupal are fine CMS platforms. I’ve taken a look and kicked the tires a bit. But here’s my biggest problem… I’ve only had one client ever even mention anything other than WordPress them by name. For the clients that I work with, many have some sort of familiarity with WordPress, even if it’s just that they’ve heard of it before. And then we talk about the fact that CNN, UPS, TechChurch, and so many other high-profile sites run WordPress… for many, using WordPress is a forgone conclusion. Which isn’t to say that WordPress is without its faults, but it is an enabling platform that helps you bring your project online quickly without necessarily needing to dig into the code.
What are some of WordPress’s faults?
There’s plenty of naysayers out there for whatever your selection of a CMS platform turns out to be. With that in mind, in the case of WordPress, the fact that it owns a significant portion of the market has to some extent, made it a victim of its own success. Not unlike Microsoft’s Windows platform, or Google’s Android platform. If you think about the economics involved it quickly becomes obvious, the biggest players in a market tend to be the one’s targeted for malware and virus exploits simply because there are large number of targets to exploit. If I was going to identify the single biggest “problem” with WordPress – it’s that its marketshare makes it a bigger target. That same market share is also why it gets the most developer attention and why it has the most robust plug-in ecosystem. This isn’t to say that you’re better off with Joomla or Drupal – particularly if you don’t know much about those platforms, as each has its own vulnerabilities. But what I am saying is that there’s a tradeoff.
Performance
Another area that you might find folks arguing against WordPress is performance. Probably the biggest thing to keep in mind about performance is that…
- For the vast majority of even mid-size organizations, WordPress performance isn’t something you really need to give much thought to.
- If WordPress performance is a problem for you that
probably means that you have enough visitors and traffic (and revenue) to deal with the problem.
- If you’re a small site with a performance problem, your theme is probably the most likely reason.
In short though, for most folks, avoiding WordPress because of performance concerns just doesn’t hold water. For organizations that do have real performance concerns, there are several ways to address that which we’ll touch-on elsewhere in this series.
My recommendation, of course is to go the WordPress route and make good decisions as you go. And I’ll be here to help you make good decisions.